
Le problème du sac à dos, noté également KP (en anglais, Knapsack Problem) est un problème d'optimisation combinatoire. Il modélise une situation analogue au remplissage d'un sac à dos, ne pouvant supporter plus d'un certain poids, avec tout ou partie d'un ensemble d'objets ayant chacun un poids et une valeur. Les objets mis dans le sac à dos doivent maximiser la valeur totale, sans dépasser le poids maximum.
Dans la recherche [modifier]
Le problème du sac à dos est l'un des 21 problèmes NP-complets de Richard Karp, exposés dans son article de 1972. Il est intensivement étudié depuis le milieu du XXe siècle et on trouve des références dès 1897, dans un article de George Ballard Mathews[1]. La formulation du problème est fort simple, mais sa résolution est plus complexe. Les algorithmes existants peuvent résoudre des instances pratiques de taille importante. Cependant, la structure singulière du problème, et le fait qu'il soit présent en tant que sous-problème d'autres problèmes plus généraux, en font un sujet de choix pour la recherche.
Ce problème est à la base du premier algorithme de chiffrement asymétrique (ou à « clé publique ») présenté par Martin Hellman, Ralph Merkle et Whitfield Diffie à l'université Stanford en 1976[2]. Toutefois, même si l'idée est due au problème du sac à dos, RSA est considéré comme le premier véritable algorithme de chiffrement asymétrique.
La version NP-difficile de ce problème a été utilisée dans des primitives et des protocoles de cryptographie, tels que le cryptosystème de Merkle-Hellman ou le cryptosystème de Chor-Rivest. Leur avantage par rapport aux cryptosystèmes asymétriques fondés sur la difficulté de factoriser est leur rapidité de chiffrement et de déchiffrement. Cependant, l'algorithme de Hellman, Merkle et Diffie est sujet aux « portes dérobées » algorithmiques, ce qui implique qu'il est « cassé », c'est-à-dire cryptanalysé[3]. Le problème du sac à dos est un exemple classique de méprise en ce qui concerne les liens entre la NP-complétude et la cryptographie. Une version revue de l'algorithme, avec une itération du problème du sac à dos, a alors été présentée, pour être sitôt cassée[4]. Les algorithmes de chiffrement asymétrique fondés sur le sac à dos ont tous été cassés à ce jour, le dernier en date étant celui de Chor-Rivest[5].
Sous sa forme décisionnelle, le problème est NP-complet, ce qui signifie qu'il n'existe pas de méthode générale connue pour construire une solution optimale, à part l'examen systématique de toutes les solutions envisageables. Le problème d'optimisation est NP-difficile, sa résolution est au moins aussi difficile que celle du problème de décision, et il n'existe pas d'algorithme polynomial connu qui, étant donné une solution, peut dire si elle est optimale (ce qui reviendrait à dire qu'il n'existe pas de solution avec un k plus grand, donc à résoudre le problème de décision NP-complet).
http://fr.wikipedia.org/wiki/Th%C3%A9orie_de_la_complexit%C3%A9_des_algorithmes
Introduction [modifier]
Un problème informatique est résolu par un algorithme, ce dernier est composé d'un ensemble d'étapes simples qui permettent d'obtenir un résultat au problème donné. Souvent, le nombre d'étapes nécessaires à la résolution varie en fonction du nombre d'éléments à traiter. Pour un même problème, plusieurs algorithmes peuvent aussi exister. La complexité d'un algorithme représente le nombre d'étapes qui seront nécessaires pour traiter un problème donné pour une entrée de taille donnée.
Supposons que le problème posé soit de trouver un nom dans un annuaire téléphonique. Il existe plusieurs méthodes pour rechercher le nom :
Pour chacune de ces méthodes il existe un pire cas et un meilleur cas. Prenons la méthode 1 :
Si l'annuaire contient 30000 noms, le pire des cas demandera plus d'étapes que si l'annuaire contient 3 noms. La complexité de cette première méthode est évaluée à O(n) : il faut parcourir tous les noms (n noms) une fois dans le pire des cas pour n entrées dans l'annuaire fourni.
Le second algorithme demandera dans le pire des cas de séparer en deux l'annuaire, puis de séparer à nouveau cette sous partie en deux, ainsi de suite jusqu'à n'avoir qu'une seule page. Le nombre d'étapes nécessaire sera log2n. La complexité de ce second algorithme dans le pire des cas sera alors évaluée à O(logn).
Problème algorithmique [modifier]
Un problème algorithmique est un problème posé de façon mathématique, c'est-à-dire qu'il est énoncé rigoureusement dans le langage des mathématiques – le mieux étant d'utiliser le calcul des prédicats. Il comprend des hypothèses, des données[1] et une question. On distingue deux types de problèmes :
Dans chaque catégorie de problèmes ci-dessus, on dit qu'un problème a une réponse algorithmique si sa réponse peut être fournie par un algorithme. Un problème est décidable s'il s'agit d'un problème de décision – donc d'un problème dont la réponse est soit oui soit non – et si sa réponse peut être fournie par un algorithme. Symétriquement, un problème est calculable s'il s'agit d'un problème d'existence et si l'élément calculé peut être fourni par un algorithme. La théorie de la complexité ne couvre que les problèmes décidables ou calculables et cherche à évaluer les ressources – temps et espace mémoire – mobilisées pour obtenir algorithmiquement la réponse.
La théorie de la complexité vise à savoir si la réponse à un problème peut être donnée très efficacement, efficacement ou au contraire être inatteignable en pratique (et en théorie), avec des niveaux intermédiaires de difficulté entre les deux extrêmes ; pour cela, elle se fonde sur une estimation – théorique – des temps de calcul et des besoins en mémoire informatique. Dans le but de mieux comprendre comment les problèmes se placent les uns par rapport aux autres, la théorie de la complexité établit des hiérarchies de difficultés entre les problèmes algorithmiques, dont les niveaux sont appelés des « classes de complexité ». Ces hiérarchies comportent des ramifications, suivant que l'on considère des calculs déterministes – l'état suivant du calcul est « déterminé » par l'état courant – ou non déterministes.
Un problème d'existence peut être transformé en un problème de décision équivalent. Par exemple, le problème du voyageur de commerce qui cherche, dans un graphe dont les arêtes sont étiquetées par des coûts, à trouver un cycle, de coût minimum, passant une fois par chaque sommet, peut s'énoncer en un problème de décision comme suit : Existe-t-il un cycle passant une fois par chaque sommet tel que tout autre cycle passant par tous les sommets ait un coût supérieur. L'équivalence de ces deux problèmes suppose que la démonstration d'existence repose sur un argument constructif[2], c'est-à-dire, par exemple dans le cas du voyageur de commerce, fournit effectivement un cycle de coût minimum dans le cas où on a montré qu'un cycle de coût minimum existe. Le problème de l'existence d'un cycle de coût minimum est équivalent au problème du voyageur de commerce, au sens où si l'on sait résoudre efficacement l'un, on sait aussi résoudre efficacement l'autre. Dans la suite de cet article, nous ne parlerons donc que de problème de décision.
http://fr.wikipedia.org/wiki/Th%C3%A9orie_de_la_complexit%C3%A9_des_algorithmes
Le problème ouvert P=NP [modifier]
On a clairement P ⊆ NP car un algorithme déterministe est un algorithme non déterministe particulier, ce qui, dit en mots plus simples, signifie que si une solution peut être calculée en temps polynomial, alors elle peut être vérifiée en temps polynomial. En revanche, la réciproque : NP ⊆ P, qui est la véritable difficulté de l'égalité P = NP est un problème ouvert central d'informatique théorique. Il a été posé en 1970 indépendamment par Stephen Cook et Leonid Levin ; en 2000, l'institut Clay a mis ce problème dans sa liste des sept problèmes du prix du millénaire, proposant une récompense de plus de 1 000 000 $ à qui parviendra à décider si P et NP sont différents ou égaux.
La plupart des spécialistes conjecturent que les problèmes NP-complets ne sont pas solubles en un temps polynomial (donc, que P ≠ NP). Cela ne signifie pas pour autant que toute tentative de résoudre un problème NP-complet est vaine (voir la section « Résolution » de l'article sur la NP-complétude). Il existe de nombreuses approches (qui se sont finalement révélées irrémédiablement erronées) attaquant le problème P ≠ NP ; le spécialiste de la théorie de la compléxité Gerhard Woeginger maintient une liste de ces erreurs [1]. La revendication récente (6 août 2010) de Vinay Deolalikar, travaillant aux HP Labs, d'une démonstration de P ≠ NP a été la première à faire l'objet d'une attention relativement importante de nombreux mathématiciens et informaticiens de renoms, que ce soit sous la forme d'échanges dans des blogs ([2], [3], [4]), de journaux en ligne ou sous la forme plus construite d'un projet d'étude collaborative en ligne (du type projet "polymath" tel que promu par les médaillés Fields Terence Tao et Tim Gowers). Cette étude collaborative donne la liste des points où l'approche de Vinay Deolalikar achoppe actuellement [5].
Un compresseur sans perte universel ne peut pas exister. Plus précisément, pour tout compresseur sans perte, on est certain que :
http://fr.wikipedia.org/wiki/Paradoxe_du_compresseur
Ces propriétés sont démontrées ci-après. Cependant, elles n'enlèvent rien à l'intérêt des compresseurs sans perte. En effet, dans la pratique, les mots, messages ou fichiers que l'on souhaite compresser ne sont pas quelconques et choisis aléatoirement parmi tous les mots, messages ou fichiers possibles. Les compresseurs se servent de leurs particularités. Des compresseurs seront alors très bons avec certains types de données, et très mauvais avec d'autres.
Ainsi pour ces types de compresseurs spécialisés, l'information fournie par le contexte est utilisée pour la compression (voir théorie de l'information).
Expérimentation [modifier]
On peut aisément vérifier expérimentalement cette impossibilité. Voici un script shell qui crée un fichier comportant 100 fois la ligne "blabla" puis qui effectue 100 compressions successives de ce fichier à l'aide du compresseur gzip et enfin affiche les tailles successives obtenues :
for i in `seq 1 100`; do echo "blabla" >> toto001; done
for i in `seq 1 100`; do gzip -c "toto`printf "%03d" $i`" > "toto`printf "%03d" $((i+1))`"; done
wc -c toto*
On vérifie souvent en pratique qu'un fichier qui est déjà le résultat d'une compression se compresse mal, voire grossit par application du compresseur. D'ailleurs, gzip refuse par défaut de compresser les fichiers comportant l'extension ".gz" qui est le signe d'une précédente application de ce compresseur.
Un compresseur sans perte peut être vu comme une injection des mots dans les mots, c'est-à-dire une fonction C telle que
On vérifie alors aisément que, pour tout mot u, l'un des deux cas suivants est vérifié :
 il existe un entier k tel que le mot Ck(u) est de taille supérieure à N.
il existe un entier k tel que le mot Ck(u) est de taille supérieure à N. Ceci montre la troisième propriété de l'impossibilité énoncée ci-dessus. Les deux premières en découlent car, s'il y a compression stricte, c'est-à-dire s'il existe un mot u plus grand que sa version compressée C(u), alors :
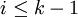 tel que le mot Ci(u) est strictement plus petit que sa version compressée Ci + 1(u),
tel que le mot Ci(u) est strictement plus petit que sa version compressée Ci + 1(u), On peut remarquer par ailleurs qu'il est impossible de compresser strictement tous les mots d'une taille N donnée : en effet il y a aN mots de taille N pour un alphabet à a lettres et seulement  mots avec strictement moins de N lettres.
mots avec strictement moins de N lettres.
http://fr.wikipedia.org/wiki/Complexit%C3%A9
Les exemples étudiés dans les livres sont souvent simples mais la réalité l’est beaucoup moins. On peut dire qu’en première approximation les systèmes complexes sont tous les systèmes. La complexité est la règle, la simplicité l’exception. La complexité est un défi pour les mathématiques appliquées : utiliser les mathématiques pour comprendre tout ce qui est sous nos yeux, ne pas se limiter à ce qu’on peut tracer à la règle et au compas.
Tous les systèmes réels sont complexes, ou presque tous. Mais plus un système est complexe, plus il est difficile de le connaître avec précision. Le nombre des combinaisons possibles par exemple pose problème. Comme les parties sont interdépendantes, les états envisageables a priori sont toutes les combinaisons d’états des partie. L’explosion combinatoire conduit à des nombres gigantesques de cas possibles, souvent plus que le nombre de particules dans l’univers connu, même pour des systèmes relativement peu complexes. La connaissance précise de l’état présent d’un système complexe pose également problème. Il y a beaucoup trop de variables d’état à mesurer. Les systèmes complexes sont souvent mal connus et ils réservent beaucoup de surprises (émergence de propriétés collectives, auto-organisation, nombres de Feigenbaum dans les systèmes chaotiques). L’Institut de Santa Fe, créé par plusieurs physiciens dont Murray Gell-Mann et dont le nom officiel est Institute for complexity, fait de l’étude de ce type de questions son activité à plein temps.
Appréhender la complexité est de plus en plus nécessaire, et peut être un des buts majeurs du 21 siècles et de rendre compte de la complexité du monde, en la définissant dans un premier temps, puis de l'étudier dans des cas particuliers. Edgar Morin, grand sociologue et philosophe propose dans "introduction à la complexité" une belle approche de cette inconnue qu'est la complexité. La compréhension de la complexité du réel semble de plus en plus importante au fil du temps. Il faudrait mettre l'accent sur la capacité qu'a la complexité à remettre tout en question. Elle est l'entremêlement de plusieurs paramètres qui s'influencent les uns les autres. Or les hommes ont souvent isolé des définitions sans les mettre en relation les unes les autres ce qui a ralenti le processus de compréhension de la complexité du réel. L'homme n'a pas toujours eu le choix, pour comprendre des phénomènes de n'importe quelle nature, il faut diviser, et parcelliser, pour ensuite comprendre l'ensemble. Mais cette parcellisation n'est pas propice à la compréhension de la complexité, paradoxalement la compréhension de la complexité a besoin de prendre en compte tous les paramètres en jeux, et donc de les isoler avant.
La théorie générale des systèmes est parfois appelée systémique.
La redondance n'est pas la répétition à l'identique, mais le déploiement d'une multitude de versions différentes d'un même schéma ou motif (en anglais pattern).
Alors, il est possible de modéliser la complexité en termes de redondance fonctionnelle, comme le restaurant chinois où plusieurs fonctions sont effectuées en un même endroit d'une structure.
Pour la complication, le modèle serait la redondance structurelle d'une usine où une même fonction est exécutée en plusieurs endroits différents d'une structure.
http://fr.wikipedia.org/wiki/Machine_de_Turing_non_d%C3%A9terministe
http://fr.wikipedia.org/wiki/R%C3%A9duction_polynomiale
Un léger problème se pose cependant : il est possible que des éléments de  ne correspondent à aucune instance du problème (autrement dit, qu'ils n'ont aucun antécédent). Par commodité, on supposera que toute chaîne de ce type a pour image 0.
ne correspondent à aucune instance du problème (autrement dit, qu'ils n'ont aucun antécédent). Par commodité, on supposera que toute chaîne de ce type a pour image 0.
http://fr.wikipedia.org/wiki/Programmation_dynamique
Principe [modifier]
La programmation dynamique s'appuie sur un principe simple : toute solution optimale s'appuie elle-même sur des sous-problèmes résolus localement de façon optimale[1]. Concrètement, cela signifie que l'on va pouvoir déduire la solution optimale d'un problème en combinant des solutions optimales d'une série de sous problèmes. Les solutions des problèmes sont étudiées 'de bas en haut', c'est-à-dire qu'on calcule les solutions des sous-problèmes les plus petits pour ensuite déduire petit à petit les solutions de l'ensemble.
Par exemple pour optimiser la production de 30 puits à budget donné, on optimise la gestion de 2 puits pour tout budget inférieur ou égal[2], puis on considère l'ensemble comme un puits unique et on ajoute les puits suivants un par un.
Un autre exemple est le problème du sac à dos.





















